Variable Types#
Module: leaspy.variables.specs
Every node in the Variables DAG is an instance of one of six Python classes from leaspy.variables.specs. Understanding what each class means is the core skill for declaring variables in a new model via get_variables_specs().
Class Hierarchy#
VariableInterface (abstract base)
├── IndepVariable (no dependencies on other variables — root nodes in the DAG)
│ ├── Hyperparameter — fixed constant, never learned
│ ├── DataVariable — observed input data (t, y, ...)
│ ├── ModelParameter — M-step: updated by SAEM maximization
│ └── LatentVariable — E-step: sampled by MCMC
│ ├── PopulationLatentVariable — one value shared across all patients
│ └── IndividualLatentVariable — one value per patient
└── LinkedVariable — deterministically computed from parents
All types share two boolean class attributes that the DAG and the State use:
Attribute |
Meaning |
Practical effect |
|---|---|---|
|
Can the State accept a direct assignment ( |
If |
|
Is the tensor shape determined by the model alone, without needing the dataset? |
If |
Class |
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Color Legend#
The colors in the DAG diagrams map directly to Python classes:
Color |
Class |
Role |
|---|---|---|
pink |
|
Fixed constant — set at definition time, never modified |
orange |
|
Estimated quantity — updated by the M-step each iteration |
plum |
|
Population-level random effect — sampled by MCMC in the E-step |
blue |
|
Per-patient random effect — sampled per individual in the E-step |
green |
|
Deterministic function of other variables — no independent value |
white |
|
Observed input — injected from the dataset at runtime |
wheat |
(visual convention) |
Observation model (likelihood / NLL) — built by |
An Illustrated Example — Temporal Variability#
This sub-graph governs when each patient is positioned on the disease timeline. It is the smallest self-contained sub-graph of the Logistic model — yet it already contains five of the six variable types.
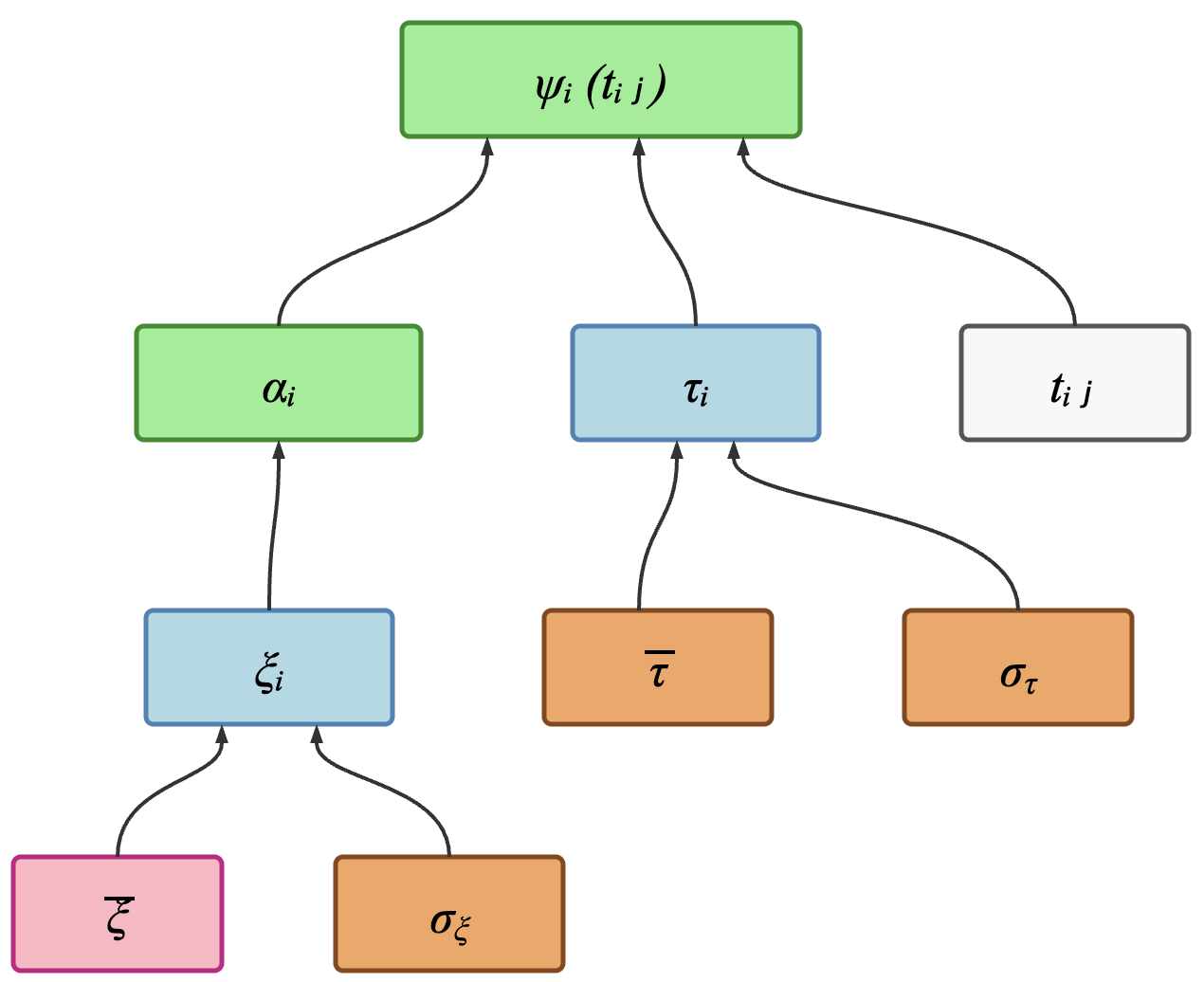
Reading this diagram:
Pink roots (
xi_mean): a constant baked into the model definition.xi_mean = 0sets the prior mean acceleration to \(e^0 = 1\). Declared asHyperparameter(0.0).Orange roots (
xi_std,tau_mean,tau_std): estimated by the M-step. Declared with factories likeModelParameter.for_ind_std("xi", shape=(1,)).Blue intermediate nodes (
xi,tau): per-patient random effects. Declared asIndividualLatentVariable(Normal("xi_mean", "xi_std")). The prior is symbolic — it reads current values from the State at each E-step rather than fixing them at construction.White root (
t): observed visit ages. Declared asDataVariable().Green leaves (
alpha,rt): pure deterministic transforms.alpha = exp(xi)is declared asLinkedVariable(Exp("xi"))— the keyword argument namexiwires the edge automatically.rtusestime_reparametrization(*, t, alpha, tau), which wires all three edges.
Variable Types#
DataVariable() # no arguments
A root node holding observed input data injected from the dataset before each E-step. Shape is unknown at definition time (depends on cohort size), so fixed_shape = False.
# In McmcSaemCompatibleModel.get_variables_specs()
t = DataVariable() # observed visit ages — shape (Ni, Nt) at runtime
# In ObservationModel.get_variables_specs()
y = DataVariable() # observed biomarkers — shape (Ni, Nt, Nfts) at runtime
Hyperparameter(value) # value: scalar, list, or torch.Tensor
A root node holding a fixed constant — set once at model definition, never touched during fitting. Scalars are auto-cast to torch.Tensor.
# In RiemanianManifoldModel.get_variables_specs()
xi_mean = Hyperparameter(0.0) # prior mean of log-acceleration, fixed at 0
log_v0_std = Hyperparameter(0.01) # tight prior std, keeps log_v0 close to log_v0_mean
# In LogisticModel.get_variables_specs()
log_g_std = Hyperparameter(0.01) # tight prior std, keeps log_g close to log_g_mean
ModelParameter(shape, suff_stats, update_rule, update_rule_burn_in=None)
A root node that is estimated by the M-step each SAEM iteration. The algorithm gathers sufficient statistics from current E-step samples, then applies update_rule to compute a new value.
Argument |
What to provide |
|---|---|
|
Fixed tensor shape, e.g. |
|
A |
|
Keyword-only function |
|
(optional) Alternative memory-less rule for the burn-in phase |
Writing this by hand is verbose. Use the factory shortcuts for the common cases:
Factory |
Use when… |
|---|---|
|
Prior mean of a population latent variable |
|
Prior mean of an individual latent variable |
|
Prior std-dev of an individual latent variable (includes SAEM correction) |
# In LogisticModel.get_variables_specs()
log_g_mean = ModelParameter.for_pop_mean("log_g", shape=(self.dimension,))
# In TimeReparametrizedModel.get_variables_specs()
tau_mean = ModelParameter.for_ind_mean("tau", shape=(1,))
tau_std = ModelParameter.for_ind_std("tau", shape=(1,))
xi_std = ModelParameter.for_ind_std("xi", shape=(1,))
PopulationLatentVariable(prior, sampling_kws=None)
A population-level random effect: one tensor shared by all patients, sampled by MCMC (Gibbs) in the E-step. Its shape is fixed (depends only on model hyperparameters, not cohort size).
The prior argument is a symbolic distribution — Normal("log_g_mean", "log_g_std") does not fix the parameters at construction time. It reads their current values from the State at each E-step, so the prior evolves as the M-step updates the means and std-devs.
# In LogisticModel.get_variables_specs()
log_g = PopulationLatentVariable(Normal("log_g_mean", "log_g_std"))
# In RiemanianManifoldModel.get_variables_specs()
log_v0 = PopulationLatentVariable(Normal("log_v0_mean", "log_v0_std"))
# In TimeReparametrizedModel.get_variables_specs()
betas = PopulationLatentVariable(Normal("betas_mean", "betas_std"),
sampling_kws={"scale": 0.5})
scale sets the approximate variable magnitude, used to initialize the Gibbs proposal standard deviation.
When to use vs ModelParameter: use PopulationLatentVariable when the quantity benefits from MCMC uncertainty quantification and a proper prior, rather than a closed-form M-step update.
IndividualLatentVariable(prior, sampling_kws=None)
A per-patient random effect: one realization per individual, sampled per patient in the E-step. Its leading dimension is n_individuals, which is unknown until the dataset is loaded — hence fixed_shape = False.
The prior works identically to the population case but the resulting tensor has shape (n_individuals, ...).
# In TimeReparametrizedModel.get_variables_specs()
xi = IndividualLatentVariable(Normal("xi_mean", "xi_std"))
tau = IndividualLatentVariable(Normal("tau_mean", "tau_std"))
sources = IndividualLatentVariable(Normal("sources_mean", "sources_std"))
Note the asymmetry:
xi_meanis aHyperparameter(fixed at 0 by construction, since average acceleration = \(e^0 = 1\)), whiletau_meanandtau_stdareModelParameters (the average disease onset must be learned from data).
When you add any LatentVariable to a NamedVariables, the container automatically adds the associated regularity variables (nll_regul_<name>_ind, nll_regul_<name>). You never declare those manually.
LinkedVariable(f) # f: keyword-only function
A deterministic function of other variables — it has no independent value. Whenever a parent changes, the State invalidates this node’s cached value and recomputes it on demand.
The DAG infers edges automatically from the function’s keyword argument names: a function def f(*, xi) tells the DAG “I depend on xi”. The argument names must match variable names exactly.
You have two ways to define f:
Option 1 — NamedInputFunction helpers (for simple transforms):
from leaspy.utils.functional import Exp, Sqr, MatMul, OrthoBasis
# In TimeReparametrizedModel.get_variables_specs()
alpha = LinkedVariable(Exp("xi")) # exp(xi)
# In LogisticModel.get_variables_specs()
g = LinkedVariable(Exp("log_g")) # exp(log_g)
# In RiemanianManifoldModel.get_variables_specs()
metric_sqr = LinkedVariable(Sqr("metric")) # metric²
orthonormal_basis = LinkedVariable(OrthoBasis("v0", "metric_sqr")) # orthonormal basis
mixing_matrix = LinkedVariable(MatMul("orthonormal_basis", "betas").then(torch.t))
Option 2 — any callable with keyword-only arguments (static method, class method, or function):
# In TimeReparametrizedModel.get_variables_specs()
rt = LinkedVariable(self.time_reparametrization)
# def time_reparametrization(*, t, alpha, tau) → wires edges t, alpha, tau → rt
# In RiemanianManifoldModel.get_variables_specs()
model = LinkedVariable(self.model_with_sources)
# def model_with_sources(*, rt, space_shifts, metric, v0, g) → wires 5 edges
get_variables_specs() returns a NamedVariables object — a smart dictionary that:
Prevents name collisions — re-registering an existing name raises an error (critical across the inheritance chain where each parent class calls
super().get_variables_specs()then adds its own variables).Reserves short names —
"ind","pop","nll","state","suff_stats", etc. are forbidden to avoid conflicts with internal logic.Auto-generates regularity variables — adding any
LatentVariablesilently addsnll_regul_<name>_indandnll_regul_<name>asLinkedVariables, and keeps a runningnll_regul_ind_sum.Auto-adds suff-stats side-variables — if a
ModelParameter’sCollectdefines dedicated variables (e.g.xi_sqr = LinkedVariable(Sqr("xi"))), those are injected automatically.
# In LogisticModel.get_variables_specs()
def get_variables_specs(self) -> NamedVariables:
d = super().get_variables_specs() # always start from parent
d.update(
log_g_mean = ModelParameter.for_pop_mean("log_g", shape=(self.dimension,)),
log_g_std = Hyperparameter(0.01),
log_g = PopulationLatentVariable(Normal("log_g_mean", "log_g_std")),
g = LinkedVariable(Exp("log_g")),
)
return d
Used inside ModelParameter to declare which variables are harvested before the M-step:
Collect("xi", "tau") # collect existing variables by name
Collect("xi", xi_sqr=LinkedVariable(Sqr("xi"))) # also auto-create a dedicated variable
The names become keyword arguments that update_rule receives. The factory methods (for_ind_mean, for_ind_std, etc.) pre-wire the correct Collect + update_rule pair for you — you only need to build Collect manually for custom update rules.
Decision at a Glance#
Is the value OBSERVED (comes from the dataset)?
└─ YES → DataVariable()
Is the value FIXED (never updated during fit)?
└─ YES → Hyperparameter(value)
Is the value COMPUTED from other variables (no own tensor)?
└─ YES → LinkedVariable(f) ← f keyword-only; argument names = parent variable names
Does the variable need to be SAMPLED (random effect)?
├─ shared across ALL patients → PopulationLatentVariable(prior)
└─ one value PER patient → IndividualLatentVariable(prior)
Otherwise (optimized by the M-step):
└─ ModelParameter(shape, suff_stats=Collect(...), update_rule=...)
or a factory shortcut:
ModelParameter.for_ind_mean(var, shape)
ModelParameter.for_ind_std(var, shape)
ModelParameter.for_pop_mean(var, shape)
For the complete dependency graph of the Logistic model see The Variables DAG.